Marcel Mauss, il y a presque 100 ans, a démocratisé l’idée que les dons, ou les cadeaux, avaient un rôle de création de lien social allant bien au-delà du l’échange rationnel et économique. Ainsi dans la vie d’un réseau professionnel, le mois de janvier est à part. Ce mois résume la nature des interactions existantes à travers les échanges de vœux, cartes et autres cadeaux. Une carte est le signe d’une pensée, pas intéressée, alors qu’un goodies est un appel à ne pas être oublié ! Les chocolats à partager, eux, sont plus intimes et marquent un lien personnel au-delà des relations professionnelles. C’est dans ce contexte de réflexion sociologique que, mi-janvier, je suis resté perplexe devant le colis d’un partenaire, j’avais en effet sous les yeux un livre de poche, et pas n’importe lequel : La République, de Platon. Après une tentative de lecture, puis de feuilletage, j’ai finalement piteusement opté pour les fiches « résumé » sur internet pour comprendre le lien entre la data et Platon. Pas évident. Pas évident du tout. Mais finalement, le passage sur l’allégorie de la caverne m’a fait penser aux schémas classiques, quand on parle d’Intelligence Artificielle, d’interactions d’un agent avec son environnement. Etant en permanence à la recherche d’un moyen de vulgariser le sujet très flou de la gouvernance de la donnée, je me suis dit « pourquoi pas Platon en guise d’introduction ? »(*).

Il n’y a pas de réalité, seulement une représentation grâce aux informations disponibles
La fameuse allégorie de la caverne est un passage de La République. Des hommes sont enchaînés dans une « demeure souterraine ». Ils ne voient que leurs ombres projetées par un feu derrière eux et n’entendent, comme son, que leur écho sur les murs. Bref, ils ont une vision simplifiée de la réalité. Le monde supérieur, le bien, le soleil, n’est pas visible directement. D’ailleurs si un homme y accède il sera ébloui, perdu et ne s’accoutumera que s’il résiste à un retour arrière plus confortable. Par cette allégorie, Platon dénonce ce que nos cinq sens nous font percevoir comme réalité, il ne s’agit que d’une illusion alors que le monde supérieur, le monde intelligible, expose le bien absolu.
Pour Platon nos sens ne sont qu’une représentation, pâle copie, d’un niveau métaphysique qui lui est réel, absolu. Ce qui est étonnant c’est que la physique actuelle, elle aussi, nous confirme qu’à un niveau quantique notre définition de la réalité ne s’applique plus. Notre représentation du monde n’a plus de sens, il n’y a pas de fait universel. Je vous invite à lire l’excellent article de la MIT Technology Review sur le sujet. Pour faire simple, des chercheurs ont pu créer des réalités différentes concernant l’état de photons. C’est comme si le chat de Schrodinger avait été observé vivant et mort par deux personnes différentes en même temps, impossible a priori avec notre conception des faits et de la réalité.
Ainsi, quand Platon nous dit que la vraie réalité est métaphysique, la science nous confirme que notre vision du monde n’est qu’une perception, pas la réalité absolue. Si nos capteurs, nos sens, et les informations qu’ils saisissent ne sont qu’une représentation imparfaite du monde, alors la source même de nos processus de décisions est biaisée.
Ces processus sont souvent représentés par des modèles d’agents intelligents. Agents qui analysent et interagissent avec leur environnement en optimisant leur utilité.
Ce concept d’agent intelligent est utilisé dans le domaine de l’intelligence artificielle, par exemple dans la « bible » de Russel & Norvig (Artificial Intelligence, A Modern Approach) dont j’ai tiré le schéma ci-dessous.
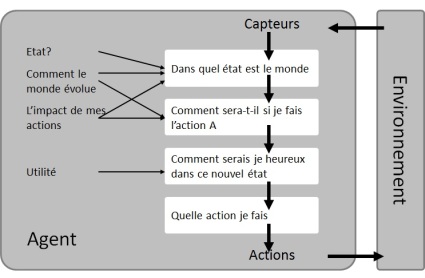
L’agent capte des informations sur son environnement, constate une situation, étudie les évolutions possibles en fonction de ses actions, évalue son utilité correspondante, choisit une action et interagit avec son environnement en conséquence. Pour ceux qui ne sont pas des machines, les vivants, « l’irrationnel » intervient à deux niveaux : tout d’abord lors de la réception des informations, nous tenons compte, en plus du visible, de nos expériences et sensations enfouies et difficiles à décrire; ensuite, lors de notre optimisation de l’utilité où le sens d’un acte a plus de valeur que l’acte lui-même. Oui oui, nous n’achetons pas le dernier iPhone pour téléphoner mais pour la représentation sociale qu’il incarne.
Si l’on revient à la question de la captation de l’information, point de départ de nos décisions, acceptons qu’elle n’est qu’une façon de représenter une réalité. Soit parce que c’est une version simplifiée de concepts plus globaux (Platon) soit parce que c’est une version macro d’un niveau plus complexe (physique quantique). Accepter cela permet de comprendre les enjeux de la gouvernance de l’information : représenter une réalité la plus fidèle possible tout en restant compréhensible et sans être ébloui.
Quelle transposition pour les entreprises ?
Si l’agent du schéma précédent était une entreprise alors l’environnement serait le marché, les clients, les concurrents, la réglementation. L’utilité serait la stratégie de l’entreprise, ses objectifs. Les capteurs sont les sources d’information et tout le travail pour les rendre exploitables, c’est-à-dire structurées, accessibles et de qualité. L’état du monde serait la description à partir des informations, l’impact de l’action A se sont les prévisions ou prédictions.
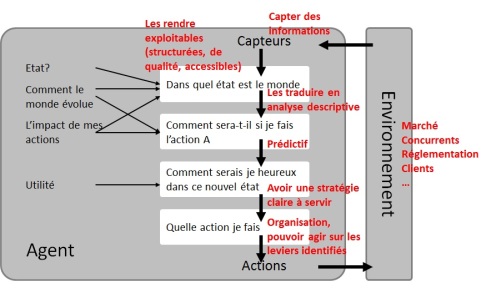
La gouvernance de l’information incarne le premier maillon de la chaîne : le dispositif de captation et préparation de l’information pour permettre de décrire le monde et anticiper l’impact des futures actions. Comme il ne s’agit que d’une représentation de la réalité, il est fondamental de penser cette discipline comme une matière vivante, en perpétuelle recherche d’amélioration au service de l’entreprise. Il n’y a pas de bonne gouvernance, il n’y a que des organisations qui font de leur mieux.
Quelle traduction concrète ?
La gouvernance de l’information, ou gouvernance de la donnée si nous parlons de numérique, n’est pas un sujet nouveau. Par exemple, dans le cas des services financiers (banques et assurances), les données représentent un actif majeur au cœur du business model. Les données ne sont évidemment pas captées et stockées n’importe comment sans contrôle, règle ou autres actions de gouvernance. D’ailleurs, certaines réglementations imposent des tâches et rôles de gouvernance : RGPD, Bale III, BCBS239, Solvabilité II etc… MAIS, parfois, le dispositif n’est pas identifié en tant que tel et donc pas pérennisé dans les organisations.
L’absence d’une stratégie et organisation de gouvernance des données n’est pas bloquante pour opérer « comme avant », le business tourne et les systèmes en place sont lourds à bouger. Cette absence est cependant rédhibitoire pour deux choses :
- casser les silos organisationnels pour une donnée transverse générant un maximum de valeur, le patrimoine data devient partagé et accessible
- être en capacité à intégrer, à grande vitesse, les nouvelles sources d’information avec la qualité et le niveau de structuration adéquates
Le dispositif pour permettre cela, la gouvernance des données, est défini par OpenDataSoft comme « un système de responsabilités et de droits de décision pour les processus en lien avec des données, exécuté selon des modèles définis. Ces modèles déterminent qui peut réaliser telle ou telle action avec quelles informations, à quel moment, dans quel contexte et à l’aide de quelles méthodes ».
Cette définition n’est pas très concrète et reste éloignée de la philosophie antique… En guise d’illustration voici une liste non exhaustive de thématiques que la gouvernance des données peut englober :
- stratégie de sourcing = comment j’obtiens mes données
- structuration des données = comment je les organise
- création et administration des glossaires, dictionnaires et catalogues de données = je maintiens et partage le patrimoine data
- création et administration des référentiels = je mets sous contrôle la liste des données vitales pour opérer une activité
- définition et suivi d’une politique de qualité des données = je mets sous contrôle la qualité de l’information utilisée pour piloter mon entreprise
- etc. Avec plein d’autres sujets possibles : la politique d’accès, la monétisation, la conformité voire même les règles d’utilisation
A cela s’ajoute, bien sûr, l’ensemble des rôles pour que tout fonctionne… Ces actions permettent de collecter et rendre exploitable un maximum d’informations pour sortir progressivement de la caverne.
Pour finir, il existe une dernière analogie amusante entre Platon et la gouvernance des données. Pouvoir cartographier ses data, savoir ce qu’elles contiennent, leur qualité, leur fraîcheur, d’où elles viennent et autres caractéristiques ; cela passe par des informations sur les données, appelées « métadonnées ». Ces métadonnées sont LE nerf de la guerre quand on parle de gouvernance de l’information. Oui, pour maîtriser l’information il faut avoir des données sur les données, ça peut paraître étonnant mais c’est ainsi. Pour les philosophes, la métaphysique « désigne la connaissance du monde, des choses ou des processus », elle « tente de décrire et d’expliquer ce qui existe vraiment ». Cette même idée que la vraie maîtrise de l’information, de la réalité, se passe dans la couche « méta », physique ou donnée, est probablement anecdotique. Elle n’en reste pas moins sympathique si l’on souhaite convaincre de l’importance capitale des métadonnées, véritable pilier de la gouvernance de l’information.
(*) : Merci beaucoup pour ce cadeau original !